















NVIDIA Tensor Core GPUs – NVIDIA B300, B200, B100, H200, H100, A100
When it comes to scaling AI infrastructure, deciding whether to wait for the NVIDIA B300 or move ahead with the H200 or B200 isn’t just a purchase decision, it’s a strategic investment in your AI roadmap. If you’re running high-performance workloads or dealing with enormous models, understanding how each GPU affects your performance, scalability, and long-term viability is key.
Let’s cut through the hype and help you decide: should you deploy now, or hold out for the next leap in AI compute?

H200 vs B200 vs B300: At-a-Glance Comparison
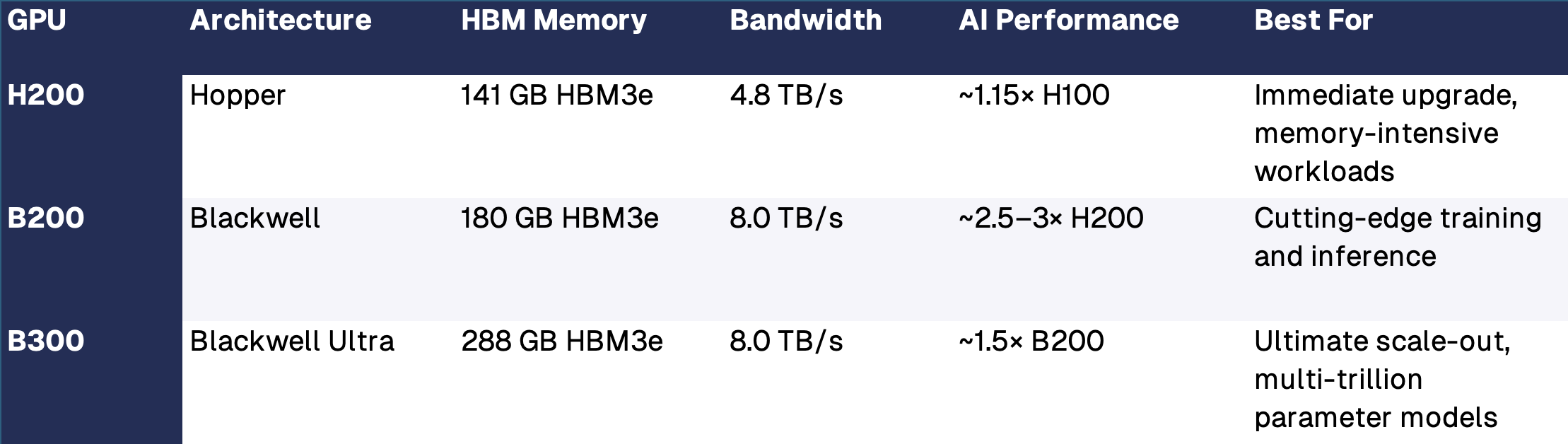
We’ve distilled the essential specs so you can compare your options:
Availability & Pricing: What to Expect
Understanding lead times and price points is crucial for planning your infrastructure investments:
NVIDIA HGX H200:
- Lead time is 4-6 weeks. OEMs are gradually transitioning focus to B200, but stock is still flowing. Price point is in the mid $200K range.
NVIDIA HGX B200:
- Lead time is typically 3-4 weeks, depending on the OEM. We’ve had excellent results working with Aivres, which has delivered units quickly and reliably. Pricing usually falls in the mid $300K range.
NVIDIA HGX B300:
- Not expected until late 2025. Pricing will likely be $400K+ given its advanced scale and premium capabilities.
Why Choose H200?
The H200 is an ideal short-term upgrade path for teams currently running Hopper-based workloads via H100 GPUs. It delivers:
- More memory (141 GB HBM3e) for training larger models
- Faster bandwidth (4.8 TB/s) over H100
- ~1.4x performance gain without needing major infrastructure overhauls
Perfect for:
- Teams that need a low-friction performance boost now without switching to a new architecture.
Why Choose B200?
The B200 is a performance leap. With a dual-die design, FP8/FP4 support, and ultra-high bandwidth, it provides:
- 2.5–3× speedup over H200
- 180 GB of HBM3e memory for heavy workloads
- Future-proofing for years of demanding AI projects
If you’re training LLMs, building AI inference platforms, or need next-gen throughput today, the B200 is ready.
Ideal for:
- Forward-looking teams investing in scalable AI infrastructure in the immediate future.
Why Wait for B300?
The B300 is designed for AI at a planetary scale. With 288 GB of HBM3e and unprecedented AI compute, it is:
- ~1.5× faster than B200, ideal for trillion-parameter models
- Engineered for massive inference clusters and high-density training farms
- Projected to ship in late 2025 with pricing likely exceeding $400K
Hold out only if:
- You’re running massive multi-node AI clusters and can delay deployment for another 6-12 months.
Choosing the Right GPU for Your AI Roadmap
Here’s a quick decision matrix:
Choose H200 if:
- You need more memory immediately.
- You want a safe upgrade from H100 without changing architecture.
- You’re under tight deployment timelines.
Choose B200 if:
- You want the best available AI performance today.
- Your models are already straining infrastructure limits.
- You’re investing in long-term scale with flexibility.
Wait for B300 if:
- You’re building for the extreme scale of next-gen AI.
- Your deployment can wait until late 2025.
- You need peak memory and compute density for future LLMs.
Wild Card Option: NVIDIA RTX PRO 6000 (Blackwell)
For teams focused on AI inference and looking for an alternative to SXM-based GPUs, the NVIDIA RTX PRO 6000 (Blackwell architecture) is a compelling option. These PCIe-based GPUs are significantly more budget-friendly than H200 or B200 servers, with 8-GPU systems starting at $115,000 USD, making them ideal for organizations scaling inference workloads without the capital demands of high-end server deployments.
Ideal for:
- Teams focused on inference-heavy tasks or edge deployments, and startups looking for performance without breaking the bank.
Key benefits include:
- Built on the Blackwell architecture for modern AI workloads
- High throughput with FP8/INT8 compute
- Plug-and-play PCIe form factor that integrates easily into existing infrastructure
- Excellent performance-per-dollar for inference at scale
Use case fit:
- Ideal for commercial applications where cost-efficiency, fast deployment, and power-optimized inference matter more than peak training throughput.

Arc Compute Can Help
At Arc Compute, we help teams navigate complex GPU decisions. Whether you’re upgrading, scaling, or preparing for next-gen AI, we can help you:
- Compare OEM lead times and pricing
- Optimize your deployment window
- Build a roadmap for hybrid GPU adoption
Add to wishlist
-
When it comes to scaling AI infrastructure, deciding whether to wait for the NVIDIA B300 or move ahead with the H200 or B200 isn’t just a purchase decision, it’s a strategic investment in your AI roadmap. If you’re running high-performance workloads or dealing with enormous models, understanding how each GPU affects your performance, scalability, and long-term viability is key.
Let’s cut through the hype and help you decide: should you deploy now, or hold out for the next leap in AI compute?
H200 vs B200 vs B300: At-a-Glance Comparison
We’ve distilled the essential specs so you can compare your options:
NVIDIA H200 vs B200 vs B300: Architecture, memory, bandwidth, and AI performance at a glance.
Availability & Pricing: What to Expect
Understanding lead times and price points is crucial for planning your infrastructure investments:
NVIDIA HGX H200:
- Lead time is 4-6 weeks. OEMs are gradually transitioning focus to B200, but stock is still flowing. Price point is in the mid $200K range.
NVIDIA HGX B200:
- Lead time is typically 3-4 weeks, depending on the OEM. We’ve had excellent results working with Aivres, which has delivered units quickly and reliably. Pricing usually falls in the mid $300K range.
NVIDIA HGX B300:
- Not expected until late 2025. Pricing will likely be $400K+ given its advanced scale and premium capabilities.
Why Choose H200?
The H200 is an ideal short-term upgrade path for teams currently running Hopper-based workloads via H100 GPUs. It delivers:
- More memory (141 GB HBM3e) for training larger models
- Faster bandwidth (4.8 TB/s) over H100
- ~1.4x performance gain without needing major infrastructure overhauls
Perfect for:
- Teams that need a low-friction performance boost now without switching to a new architecture.
Why Choose B200?
The B200 is a performance leap. With a dual-die design, FP8/FP4 support, and ultra-high bandwidth, it provides:
- 2.5–3× speedup over H200
- 180 GB of HBM3e memory for heavy workloads
- Future-proofing for years of demanding AI projects
If you’re training LLMs, building AI inference platforms, or need next-gen throughput today, the B200 is ready.
Ideal for:
- Forward-looking teams investing in scalable AI infrastructure in the immediate future.
Why Wait for B300?
The B300 is designed for AI at a planetary scale. With 288 GB of HBM3e and unprecedented AI compute, it is:
- ~1.5× faster than B200, ideal for trillion-parameter models
- Engineered for massive inference clusters and high-density training farms
- Projected to ship in late 2025 with pricing likely exceeding $400K
Hold out only if:
- You’re running massive multi-node AI clusters and can delay deployment for another 6-12 months.
Choosing the Right GPU for Your AI Roadmap
Here’s a quick decision matrix:
Choose H200 if:
- You need more memory immediately.
- You want a safe upgrade from H100 without changing architecture.
- You’re under tight deployment timelines.
Choose B200 if:
- You want the best available AI performance today.
- Your models are already straining infrastructure limits.
- You’re investing in long-term scale with flexibility.
Wait for B300 if:
- You’re building for the extreme scale of next-gen AI.
- Your deployment can wait until late 2025.
- You need peak memory and compute density for future LLMs.
Wild Card Option: NVIDIA RTX PRO 6000 (Blackwell)
For teams focused on AI inference and looking for an alternative to SXM-based GPUs, the NVIDIA RTX PRO 6000 (Blackwell architecture) is a compelling option. These PCIe-based GPUs are significantly more budget-friendly than H200 or B200 servers, with 8-GPU systems starting at $115,000 USD, making them ideal for organizations scaling inference workloads without the capital demands of high-end server deployments.
Ideal for:
- Teams focused on inference-heavy tasks or edge deployments, and startups looking for performance without breaking the bank.
Key benefits include:
- Built on the Blackwell architecture for modern AI workloads
- High throughput with FP8/INT8 compute
- Plug-and-play PCIe form factor that integrates easily into existing infrastructure
- Excellent performance-per-dollar for inference at scale
Use case fit:
- Ideal for commercial applications where cost-efficiency, fast deployment, and power-optimized inference matter more than peak training throughput.
NVIDIA RTX PRO 6000 (Blackwell)
Arc Compute Can Help
At Arc Compute, we help teams navigate complex GPU decisions. Whether you’re upgrading, scaling, or preparing for next-gen AI, we can help you:
- Compare OEM lead times and pricing
- Optimize your deployment window
- Build a roadmap for hybrid GPU adoption




Reviews
There are no reviews yet.